目前比较流行的个性化推荐算法有以下几种:
- 基于内容的推荐:根据内容本身的属性(特征向量)所作的推荐。
- 基于关联规则的推荐:“啤酒与尿布”的方式,是一种动态的推荐,能够实时对用户的行为作出推荐。是基于物品之间的特征关联性所做的推荐,在某种情况下会退化为物品协同过滤推荐。
- 协同过滤推荐:与基于关联规则的推荐相比是一种静态方式的推荐,是根据用户已有的历史行为作分析的基础上做的推荐。可分为物品协同过滤、用户协同过滤、基于模型的协同过滤。其中,基于模型的协同又可以分为以下几种类型:基于距离的协同过滤;基于矩阵分解的协同过滤,即Latent Factor Model(SVD)或者ALS;基于图模型协同,即Graph,也叫社会网络图模型。
本文所讲述的基于内容和用户画像的个性化推荐属于第一种。对于此种推荐,有两个实体:内容和用户,因此需要有一个联系这两者的东西,即为标签。内容转换为标签即为内容特征化,用户则称为用户特征化。对于此种推荐,主要分为以下几个关键部分:
- 标签库
- 内容特征化
- 用户特征化
- 隐语义推荐
综合上面讲述的各个部分即可实现一个基于内容和用户画像的个性化推荐系统。如下图所示:
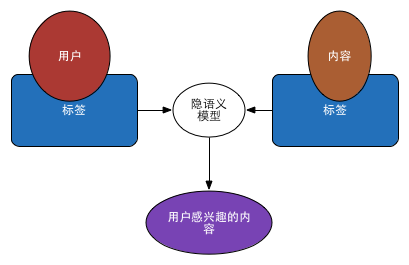
标签库
标签是联系用户与物品、内容以及物品、内容之间的纽带,也是反应用户兴趣的重要数据源。标签库的最终用途在于对用户进行行为、属性标记。是将其他实体转换为计算机可以理解的语言关键的一步。
标签库则是对标签进行聚合的系统,包括对标签的管理、更新等。
一般来说,标签是以层级的形式组织的。可以有一级维度、二级维度等。
标签的来源主要有:
- 已有内容的标签
- 网络抓取流行标签
- 对运营的内容进行关键词提取
对于内容的关键词提取,使用结巴分词 + TFIDF即可。此外,也可以使用TextRank来提取内容关键词。
这里需要注意的一点是对于关联标签的处理,比如用户的标签是足球,而内容的标签是德甲、英超,那么用户和内容是无法联系在一起的。最简单的方式是人工设置关联标签,此外也可以使用word2vec一类工具对标签做聚类处理,构建主题模型,将德甲、英超聚类到足球下面。
内容特征化
内容特征化即给内容打标签。目前有两种方式:
- 人工打标签
- 机器自动打标签
针对机器自动打标签,需要采取机器学习的相关算法来实现,即针对一系列给定的标签,给内容选取其中匹配度最高的几个标签。这不同于通常的分类和聚类算法。可以采取使用分词 + Word2Vec来实现,过程如下:
- 将文本语料进行分词,以空格,tab隔开都可以,使用结巴分词。
- 使用word2vec训练词的相似度模型。
- 使用tfidf提取内容的关键词A,B,C。
- 遍历每一个标签,计算关键词与此标签的相似度之和。
- 取出TopN相似度最高的标签即为此内容的标签。
此外,可以使用文本主题挖掘相关技术,对内容进行特征化。这也分为两种情况:
- 通用情况下,只是为了效果优化的特征提取,那么可以使用非监督学习的主题模型算法。如LSA、PLSI和GaP模型或者LDA模型。
- 在和业务强相关时,需要在业务特定的标签体系下给内容打上适合的标签。这时候需要使用的是监督学习的主题模型。如sLDA、HSLDA等。
用户特征化
用户特征化即为用户打标签。通过用户的行为日志和一定的模型算法得到用户的每个标签的权重。
- 用户对内容的行为:点赞、不感兴趣、点击、浏览。对用户的反馈行为如点赞赋予权值1,不感兴趣赋予-1;对于用户的浏览行为,则可使用点击/浏览作为权值。
- 对内容发生的行为可以认为对此内容所带的标签的行为。
- 用户的兴趣是时间衰减的,即离当前时间越远的兴趣比重越低。时间衰减函数使用1/[log(t)+1], t为事件发生的时间距离当前时间的大小。
- 要考虑到热门内容会干预用户的标签,需要对热门内容进行降权。使用click/pv作为用户浏览行为权值即可达到此目的。
- 此外,还需要考虑噪声的干扰,如标题党等。
另,在非业务强相关的情况下,还可以考虑使用LSA主题模型等矩阵分解的方式对用户进行标签化。
隐语义推荐
有了内容特征和用户特征,可以使用隐语义模型进行推荐。这里可以使用其简化形式,以达到实时计算的目的。
用户对于某一个内容的兴趣度(可以认为是CTR):
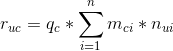
其中i=1…N是内容c具有的标签,m(ci)指的内容c和标签i的关联度(可以简单认为是1),n(ui)指的是用户u的标签i的权重值,当用户不具有此标签时n(ui)=0,q©指的是内容c的质量,可以使用点击率(click/pv)表示。